
As I prepared for the CompTIA DataSys+ exam, I gathered a series of notes and observations that helped me deepen my understanding of the database concepts which are covered in the exam's syllabus. In this post, I’m sharing some of those details. Some of the topics discussed extend beyond the scope of the exam, and not everything included in the exam's syllabus is documented.
This post also contains details of the test database I designed for hands-on practice. While these notes reflect my own learning process, they might provide useful context or inspiration for anyone exploring database management in their own studies. Therefore, this post covers:
- Information about the database I designed for hands-on practice with database management.
- My revision notes summarising key database concepts (some of which go beyond what is required for the DataSys+ exam).
NOTE: These notes are primarily intended as a personal reference, but if you find them useful, that’s an added benefit. Please keep in mind that this content is shared here as a way for me to organise and store my own thoughts and learning.
Test MySQL Database
The test database is deployed using a MySQL docker container. This section goes through the setup of the client, the container setup, the DDL (Data Definition Language) creation and the data import.
Environment Creation (MySQL Docker Container)
- Install the MySQL client (and add it to my path) on my mac using homebrew:
brew install mysql-client
echo 'export PATH="/opt/homebrew/opt/mysql-client/bin:$PATH"' >> ~/.zshrc
- Docker command to run a mysql instance:
docker run -d \
-p 3306:3306 \
--name mysql-container \
-e MYSQL_ROOT_PASSWORD=scranton123 \
-v ~/github/DUNDER_MIFFLIN_DB/csv:/var/lib/mysql-files/csv \
-v ~/github/DUNDER_MIFFLIN_DB/sql:/var/lib/mysql-files/sql \
mysql:latest
NOTE: If you need a shell on the container, you can obtain one by executing the following command:
docker exec -it mysql-container bash. If the docker container doesn’t start (or immediately exits) then check the logs usingdocker logs mysql-container
- To successfully connect to the MySQL server inside the container, you need to specify 127.0.0.1 instead of localhost. This forces the client to use TCP/IP rather than a Unix socket, allowing it to properly communicate with the containerised MySQL instance via the loopback network interface.
mysql -h 127.0.0.1 -u root -p
- Create a database called
DUNDER_MIFFLINat the mysql prompt.
CREATE database DUNDER_MIFFLIN;
- Next, we need to create the DDL (Data Definition Language) which is the SQL which defines how our database is structured. To do this open a different terminal window and create a file called
DUNDER_MIFFLIN.SQLon your local machine, with the following contents:
-- Create the product_categories table
CREATE TABLE product_categories (
category_id INT AUTO_INCREMENT PRIMARY KEY,
category_name VARCHAR(255),
category_description TEXT
);
-- Create the suppliers table
CREATE TABLE suppliers (
supplier_id INT AUTO_INCREMENT PRIMARY KEY,
supplier_name VARCHAR(255),
supplier_contact VARCHAR(255),
supplier_addr_street VARCHAR(255),
supplier_addr_city VARCHAR(255),
supplier_addr_postcode VARCHAR(255),
supplier_addr_country VARCHAR(255),
supplier_phone VARCHAR(255)
);
-- Create the products table
CREATE TABLE products (
product_id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(255),
supplier_id INT,
category_id INT,
unit_detail TEXT,
price DECIMAL(10, 2),
CONSTRAINT fk_supplier FOREIGN KEY (supplier_id) REFERENCES suppliers(supplier_id),
CONSTRAINT fk_category FOREIGN KEY (category_id) REFERENCES product_categories(category_id)
);
-- Create the shippers table
CREATE TABLE shippers (
shipper_id INT AUTO_INCREMENT PRIMARY KEY,
shipper_name VARCHAR(255),
shipper_phone VARCHAR(255)
);
-- Create the customers table
CREATE TABLE customers (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
customer_name VARCHAR(255),
customer_contact VARCHAR(255),
customer_addr_street VARCHAR(255),
customer_addr_city VARCHAR(255),
customer_addr_postcode VARCHAR(255),
customer_addr_country VARCHAR(255)
);
-- Create the employees table
CREATE TABLE employees (
emp_id INT AUTO_INCREMENT PRIMARY KEY,
emp_lastname VARCHAR(255),
emp_firstname VARCHAR(255),
emp_birthdate DATE,
emp_photo VARCHAR(255),
emp_notes TEXT
);
-- Create the orders table
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT,
emp_id INT,
order_date DATE,
shipper_id INT,
CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
CONSTRAINT fk_employee FOREIGN KEY (emp_id) REFERENCES employees(emp_id),
CONSTRAINT fk_shipper FOREIGN KEY (shipper_id) REFERENCES shippers(shipper_id)
);
-- Create the order_details table
CREATE TABLE order_details (
order_detail_id INT AUTO_INCREMENT PRIMARY KEY,
order_id INT,
product_id INT,
quantity INT,
CONSTRAINT fk_order FOREIGN KEY (order_id) REFERENCES orders(order_id),
CONSTRAINT fk_product FOREIGN KEY (product_id) REFERENCES products(product_id)
);
- Load the contents of the newly created DDL file into the database (entering the password when prompted to do so) with the following command:
mysql -u root -h 127.0.0.1 -p DUNDER_MIFFLIN < ~/github/DUNDER_MIFFLIN_DB/sql/DUNDER_MIFFLIN.SQL
NOTE: I imported the SQL code in this way because I received errors at the MySQL prompt when trying to copy and paste the DDL code (all in one go) into the MySQL prompt. I found that this could also be addressed by pasting the code to create one table at a time, but it was quicker an easier to import it all in one go, using the command shown above.
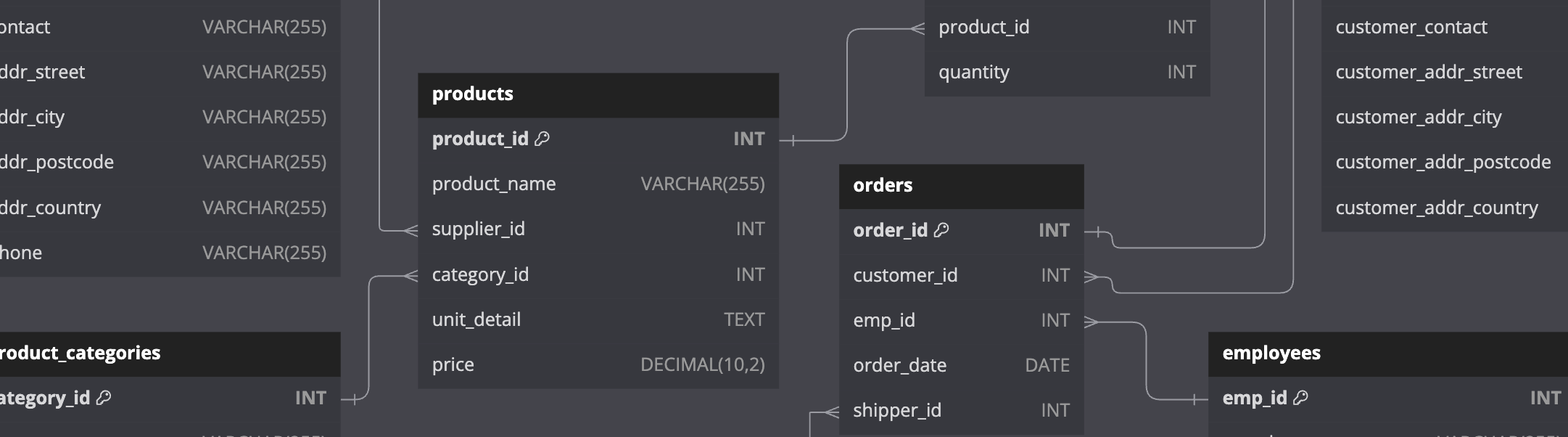
The entity relationship diagram (ERD) for the database is shown below. Click on the image to enlarge it and use your browser’s back button to return to this post.

- With the Database tables created, we can have a look and see what’s been created using the
SHOW TABLES;command:
mysql> SHOW TABLES;
+--------------------------+
| Tables_in_DUNDER_MIFFLIN |
+--------------------------+
| customers |
| employees |
| order_details |
| orders |
| product_categories |
| products |
| shippers |
| suppliers |
+--------------------------+
8 rows in set (0.02 sec)
- We can also use the
DESCRIBEcommand to show more details about an individual table:
mysql> DESCRIBE products;
+--------------+---------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+---------------+------+-----+---------+----------------+
| product_id | int | NO | PRI | NULL | auto_increment |
| product_name | varchar(255) | YES | | NULL | |
| supplier_id | int | YES | MUL | NULL | |
| category_id | int | YES | MUL | NULL | |
| unit_detail | text | YES | | NULL | |
| price | decimal(10,2) | YES | | NULL | |
+--------------+---------------+------+-----+---------+----------------+
- We now need to import some data into our database. A copy of the dummy data can be found
here
, on my GitHub page. Use
git cloneto obtain a local copy, like this:
git clone https://github.com/edrandall-dev/DUNDER_MIFFLIN_DB
NOTE: NOTE: When we executed the Docker container, we created a volume mount using the following syntax:
-v ~/github/DUNDER_MIFFLIN_DB:/var/lib/mysql-files/. This was necessary because we needed the files that are to be loaded into the database to be accessible to the Docker container, specifically in a directory that MySQL has permission to import from. By running the SQL commandSHOW VARIABLES LIKE 'secure_file_priv';, you can confirm that the directory MySQL permits for imports is/var/lib/mysql-files/
- The
LOAD DATAcomands are show below. They are contained within a single file and can be loaded into the database using the same method that we applied the DDL:
mysql -u root -h 127.0.0.1 -p DUNDER_MIFFLIN < ~/github/DUNDER_MIFFLIN_DB/sql/LOAD_DATA_INFILE.SQL
Commands to Load Data into the Database from CSV files:
LOAD DATA INFILE '/var/lib/mysql-files/csv/product_categories.csv'
INTO TABLE product_categories
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/suppliers.csv'
INTO TABLE suppliers
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/products.csv'
INTO TABLE products
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/shippers.csv'
INTO TABLE shippers
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/customers.csv'
INTO TABLE customers
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/employees.csv'
INTO TABLE employees
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/orders.csv'
INTO TABLE orders
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA INFILE '/var/lib/mysql-files/csv/order_details.csv'
INTO TABLE order_details
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
With these command sucessfuly executed, the database should now contain the dummy data:
+---------------+--------------+----------------------------+------------+-----------------------------------------------------------------------------------------------------------+
| emp_firstname | emp_lastname | employee_role | department | emp_notes |
+---------------+--------------+----------------------------+------------+-----------------------------------------------------------------------------------------------------------+
| Michael | Scott | Regional Manager | Sales | 'World's Best Boss', former regional manager, known for his inappropriate jokes and misguided leadership. |
| Jim | Halpert | Sales Representative | Sales | Prankster, romantic, and eventual co-regional manager. Later co-founds Athlead. |
| Pam | Beesly | Receptionist | Operations | Receptionist turned sales rep. Artistic, married to Jim. |
| Dwight | Schrute | Assistant Regional Manager | Sales | Beet farmer, loyal employee, often at odds with Jim, becomes regional manager. |
| Ryan | Howard | VP of Regional Sales | Sales | Started as a temp, became VP of Regional Sales, later demoted. |
| Andy | Bernard | Sales Representative | Sales | Sales rep, later regional manager, known for his love of a cappella music. |
| Phyllis | Vance | Sales Representative | Sales | Sales rep, knits at her desk, protective when needed. |
| Kevin | Malone | Accountant | Finance | Accountant, known for his chili and questionable accounting skills. |
| Toby | Flenderson | HR Representative | HR | HR rep disliked by Michael, tries to manage office chaos. |
| Stanley | Hudson | Sales Representative | Sales | Sales rep, disinterested in work, loves Pretzel Day. |
+---------------+--------------+----------------------------+------------+-----------------------------------------------------------------------------------------------------------+
We now have a database with which we can practice for the CompTIA DataSys+ Exam. This concludes the documentation related to the setup of the test MySQL database. The remainder of this blog post contains revision notes, some of which are relevant to the DataSys+ Exam.
Revision Notes
Basic Relational Algebra
Relation
A relation is another name for a table.
Tuple
A tuple is another name for a record or a row in a relational database.
Scalar
A scalar refers to a single, indivisible value. It contrasts with more complex structures such as arrays, lists, or tables. Scalars are the basic units of data in a database, and they typically include data types such as:
- Integer: A whole number, positive or negative.
- Float/Double: A number that includes a fractional part, represented in floating-point.
- String/Character: A sequence of characters, often representing text.
- Boolean: A value that can be either true or false.
- Date/Time: Values representing dates, times, or both.
Indivisible
Indivisible means that a value cannot be broken down into smaller components or elements within the context in which it is used. It is therefore considered to be a single, atomic unit of data.
For example:
- Integer: The number 42 is a scalar and is considered indivisible because it is treated as a single whole number in the context of database operations.
- String/Character: The string “hello” is a scalar and is treated as a single entity in many database operations, even though it consists of individual characters.
- Boolean: The value true or false is indivisible because it represents a single truth value and cannot be broken down further.
Primary Key
A primary key uniquely identifies a single tuple (record) in a relation (table). Some DBMSs create primary keys automatically if one is not defined in a table. Alternatively, a user created “id” field could be used.
Foreign Key
A foreign key specifies that an attribute from one relation (table) has to map to a tuple (record) in another relation
Data Manipulation Languages (DML)
These are methods to store and retrieve information from a database. There are 2 types:
-
Prodcedural - The query specifies the high-level strategy to find the desired result based on sets / bags (Relational Algebra.
-
Non-Procedural (Declarative) - The query specifies only what data is wanted and not how to find it. (Relational Calculus) Eg, SQL.
Subsets and Supersets
Let A = {1, 2}
Let B = {1, 2, 3, 4}
-
A is a subset of B because every element in A (which are 1 and 2) is also in B
-
A is a proper subset of set B if all elements of A are also elements of B and A is not equal to B. (All elements of A are in B but A is not equal to B)
-
B is a superset of A because every element in A (1 & 2) is also in B. All elements of A are in B.
-
B is a proper superset of set A if all elements of A are also elements of B and B is not equal to A (All elements of A are in B , and B is not equal to A)
Select
A select statement in SQL will choose a subset of the tuples in a relation that satisfies the selection predicate (details given in the SELECT statement). The predicate acts a filter to retain only the tuples which fulfil its qualifying requirement.
Multiple predicates and be combined to using conjunctions and disjunctions.
EG: SELECT * FROM table WHERE first_name = 'Ed'
Projection
Projection is used to select specific columns from a table, effectively creating a new table that contains only those columns. This operation is useful for focusing on specific attributes of data without retrieving the entire dataset.
| Employee ID | Name | Department | Salary |
|---|---|---|---|
| 1 | Alice | HR | 60000 |
| 2 | Bob | IT | 75000 |
| 3 | Carol | IT | 75000 |
| 4 | Dave | HR | 60000 |
A projection of the Name and Department attributes from the Employees table, would be:
| Name | Department |
|---|---|
| Alice | HR |
| Bob | IT |
| Carol | IT |
| Dave | HR |
Projection is useful in various scenarios, such as:
- Reducing the amount of data retrieved from the database by selecting only relevant columns.
- Focusing on specific attributes of the data for analysis or reporting.
- Eliminating unnecessary details from the data for further processing or operations.
Union
In relational algebra, the UNION operation is used to combine the results of two relations (tables) into a single relation that contains all the tuples (rows) from both relations, with duplicates removed. It is one of the fundamental operations in relational algebra and is similar to the union operation in set theory.
Union takes two relations (tables) and produces a new relation (table) containing all the distinct tuples (rows) that appear in either or both of the input relations - “distinct” refers to the removal of duplicate tuples (rows) from the resulting relation (table)
Example:
Relation R
| Employee ID | Name | Department |
|---|---|---|
| 1 | Alice | HR |
| 2 | Bob | IT |
Relation S
| Employee ID | Name | Department |
|---|---|---|
| 2 | Bob | IT |
| 3 | Carol | IT |
The UNION of Relation R and Relation S would be:
| Employee ID | Name | Department |
|---|---|---|
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Carol | IT |
NOTE: The
UNION ALLSQL command will perform an UNION operation but include all duplicates.
Intersection
In relational algebra, the INTERSECTION operation is used to retrieve the common tuples (rows) that exist in both of the input relations (tables). This operation results in a new relation containing only those tuples that are present in both input relations.
Relation T
| Employee ID | Name | Department |
|---|---|---|
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Carol | IT |
Relation V
| Employee ID | Name | Department |
|---|---|---|
| 2 | Bob | IT |
| 3 | Carol | IT |
| 4 | Dave | HR |
The Intersection of Relation T and Relation V would be:
| Employee ID | Name | Department | |
|---|---|---|---|
| 2 | Bob | IT | |
| 3 | Carol | IT |
Difference
In relational algebra, the DIFFERENCE operation, also known as the MINUS operation, is used to find the tuples (rows) that are present in one relation but not in another. This operation results in a new relation containing only the tuples from the first relation that do not appear in the second relation.
Product
The PRODUCT operation is denoted by the symbol ×. It takes two relations and produces a new relation by pairing each tuple from the first relation with every tuple from the second relation. In this example the input relations are A and B and the output relation is C
Relation A
| EmployeeID | Name |
|---|---|
| 1 | Alice |
| 2 | Bob |
Relation B
| DepartmentID | DepartmentName |
|---|---|
| 10 | HR |
| 20 | IT |
Relation C
| EmployeeID | Name | DepartmentID | DepartmentName |
|---|---|---|---|
| 1 | Alice | 10 | HR |
| 1 | Alice | 20 | IT |
| 2 | Bob | 10 | HR |
| 2 | Bob | 20 | IT |
The following table shows some relation algebra concepts and the corresponding SQL JOIN command:
| Relational Algebra Concept | SQL Command/Operation | Description |
|---|---|---|
| UNION | UNION |
Combines the results of two queries into a single result set, including all distinct rows from both queries. |
| INTERSECT | INTERSECT |
Returns only the rows that are present in both queries. |
| DIFFERENCE | EXCEPT or MINUS |
Returns the rows from the first query that are not present in the second query. (EXCEPT in SQL Server, PostgreSQL; MINUS in Oracle) |
| PRODUCT | Implicit Join (Comma) | Returns the product of two tables. In SQL, this is done by listing tables separated by commas in the FROM clause without a WHERE condition. |
| SELECTION | WHERE |
Filters rows based on a specified condition. |
| PROJECTION | SELECT |
Selects specific columns from a table. |
| JOIN | INNER JOIN |
Combines rows from two tables based on a related column between them. |
| LEFT OUTER JOIN | LEFT JOIN |
Returns all rows from the left table and the matched rows from the right table. Unmatched rows from the right table will contain NULL. |
| RIGHT OUTER JOIN | RIGHT JOIN |
Returns all rows from the right table and the matched rows from the left table. Unmatched rows from the left table will contain NULL. |
| FULL OUTER JOIN | FULL JOIN |
Returns rows when there is a match in one of the tables. Unmatched rows from both tables will contain NULL. |
| NATURAL JOIN | NATURAL JOIN |
Combines rows from two tables based on columns with the same name and datatype. |
| THETA JOIN | JOIN ... ON |
Combines rows from two tables based on a condition that is not necessarily equality. |
Isolation Levels & Read Phenomena
Read Phenomena
Dirty Reads (Not yet committed)
- A transaction can read data that has been modified by another transaction but not yet committed.
Non-repeatable reads (Different Data in a row)
- A transaction reads the same row twice and gets different data each time, because a transaction elsewhere has committed an update in the meantime.
Phantom Reads (Additional Rows)
- A transaction re-executes a query returning a set of rows that satisfy a condition and finds that the set of rows satisfying the condition has changed.
Isolation Levels
Read Uncommitted (Lowest Level)
- This is the lowest isolation level. Transactions can see uncommitted changes made by other transactions.
- It is rarely used because of the risk of reading uncommitted, potentially inconsistent data.
- It results in all 3 read phenomena (Dirty Reads, Non-repeatable reads, Phantom Reads)
Read Committed (PG Default)
- This is the default isolation level in many databases, including PostgreSQL.
- A transaction only sees data that has been committed before the transaction began.
- It is suitable for many applications where consistency requirements are not strict.
- It can result in Non-repeatable reads and Phantom Reads
Repeatable Read (DB Snapshot)
- A transaction sees a consistent snapshot of the database as of the start of the transaction. It does not see any changes made by other transactions after the transaction began.
- It is useful for applications that require a higher level of consistency, such as financial applications
- It can still result in Phantom Reads
Serialisable (Highest Level)
- This is the highest isolation level. Transactions are executed in such a way that they appear to be executed in a serial order, one after the other, rather than concurrently.
- It is suitable for applications that require the highest level of consistency and can tolerate the potential performance penalty
- It does not result in any read phenomena
Summary of Read Phenomena Allowed by Isolation Levels
| Isolation Level | Dirty Reads | Non-repeatable Reads | Phantom Reads |
|---|---|---|---|
| Read Uncommitted | Yes | Yes | Yes |
| Read Committed | No | Yes | Yes |
| Repeatable Read | No | No | Yes |
| Serializable | No | No | No |
Data on Disk
- The database creates files at an OS level
- Those files contain pages
- The pages contain tables
- The tables contain rows
In addition the Pages sometimes contain indexes which are used for faster data retrieval. They point to which part of the heap needs to be read to retrieve specific data. Indexes are data structures which are separate to the heap, which has pointers to the heap.
Article Understanding Database Internals: How Tables and Indexes are Stored on Disk and Queried
Index Types
| Index Type | Advantages | Disadvantages |
|---|---|---|
| B-Tree | Balanced and sorted, allows for quick lookups and ordered access. | Becomes large and slow to update if the table has many columns or rows. |
| Bitmap | Efficient for columns with limited unique values. | Not suitable for columns with many unique values. Write performance can be suffer. |
| Hash | Ideal for fast lookups using the hash key. | Poor performance when matching on a partial key. |
| Clustered | Fast access for sequential data. | Write performance suffers for non-sequential data. |
| Nonclustered | A table can have more than one. | Write performance can suffer. Requires up-to-date index statistics. |
Other Topics:
- ACID Principles
- Read Phenonema and Isolation Levels
- Views and Materialised views
- Normalisation (1NF to 5NF)
- Entity Relationship Diagrams (including arrows)
- SQL (including Joins Left / Right / Full and Nested Queries) - IMDB example on sqllite or pg_docker
- Set Based Logic (UNION, UNION ALL, INTERSECT, EXCEPT)
- Partitioning types (range / list / composite / hash)